
概要
Zynq搭載FPGA SoCボード PYNQ-Z2 のPLにビットコインマイニングアルゴリズムであるSHA256dを実装し、PynqのJupyter Notebookから実行してハッシュレートを測定する。
本記事では以下を扱う。
- HLS による SHA256d 実装
- AXI-Stream + AXI DMA 接続
- PYNQ からの実行
- PSでのhashlibとの性能比較
ビットコインマイニングそのものではなく、その前段階となるハッシュアクセラレータの構築が目的である。
SHA256dとは
メッセージに対してSHA256を2重に実施したものである。
Input: Message m
SHA256d(m) = SHA256(SHA256(m))
構成
今回のシステムは、ZynqのPS(ARM)とPL(FPGA)を分離し、それぞれの役割を明確にした構成としている。
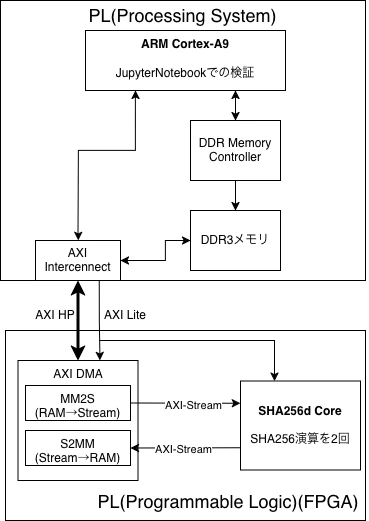
PS側は制御とメモリアクセスを担当し、PL側は純粋にSHA256dのハッシュ演算のみを実行する。
両者の間はAXIインターフェースを介して接続される。
データの流れとしては、
PSがDDRメモリ上にメッセージを配置する。
AXI DMAはこのデータをメモリから読み出し、AXI-StreamとしてPL側へストリーム転送する。
PL上のSHA256dコアはこのストリームを逐次処理し、結果を再びAXI-Streamとして出力する。
出力されたデータはDMAによって再びDDRメモリへ書き戻され、最終的にPSから参照される。
この構成におけるインターフェースの役割は明確に分離されている。
データ転送には効率的なAXI-Streamを用いる。
PLの制御にはAXI-Liteを使用する。
今回の実装では、処理するブロック数などのパラメータをレジスタ経由で設定し、処理の開始トリガを与える用途に限定している。
また、できるだけPSの介入を抑えつつ、FPGAが主体となるようなシステムにするため、メモリとストリームの橋渡しとしてAXI DMAを配置している。
PSとPLの間でデータをやり取りする際、CPUが逐次コピーを行うとオーバーヘッドが大きくなるが、DMAを用いることでメモリとストリーム間の転送をハードウェアで自動化できる。
実験環境
| 項目 | 内容 |
|---|---|
| FPGAボード | PYNQ-Z2 (Zynq XC7Z020-1CLG400C) |
| クロック | 50 MHz |
| Vivado | 2025.1 |
| Vitis HLS | 2025.1 |
HLS実装
SHA256d演算の記述は高位合成で行う。
ソース
sha256d_axis.cpp
#include <ap_int.h>
#include <ap_axi_sdata.h>
#include <hls_stream.h>
typedef ap_axiu<32, 0, 0, 0> axis32_t;
struct digest256_t {
ap_uint<32> h[8];
};
static inline ap_uint<32> rotr(ap_uint<32> x, int n) {
#pragma HLS INLINE
return (x >> n) | (x << (32 - n));
}
static void sha256_compress(const ap_uint<32> block[16], digest256_t &out) {
#pragma HLS INLINE off
static const ap_uint<32> K[64] = {
0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,
0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5,
0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,
0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174,
0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,
0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da,
0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,
0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967,
0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,
0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85,
0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,
0xd192e819,0xd6990624,0xf40e3585,0x106aa070,
0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,
0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3,
0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,
0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2
};
#pragma HLS ARRAY_PARTITION variable=K complete
ap_uint<32> W[16];
#pragma HLS ARRAY_PARTITION variable=W complete
ap_uint<32> a = 0x6a09e667;
ap_uint<32> b = 0xbb67ae85;
ap_uint<32> c = 0x3c6ef372;
ap_uint<32> d = 0xa54ff53a;
ap_uint<32> e = 0x510e527f;
ap_uint<32> f = 0x9b05688c;
ap_uint<32> g = 0x1f83d9ab;
ap_uint<32> h = 0x5be0cd19;
for (int i = 0; i < 16; i++) {
#pragma HLS UNROLL
W[i] = block[i];
}
for (int t = 0; t < 64; t++) {
#pragma HLS PIPELINE II=1
ap_uint<32> wt;
if (t < 16) {
wt = W[t];
} else {
ap_uint<32> s0 = rotr(W[(t - 15) & 15], 7) ^ rotr(W[(t - 15) & 15], 18) ^ (W[(t - 15) & 15] >> 3);
ap_uint<32> s1 = rotr(W[(t - 2) & 15], 17) ^ rotr(W[(t - 2) & 15], 19) ^ (W[(t - 2) & 15] >> 10);
wt = W[t & 15] + s0 + W[(t - 7) & 15] + s1;
W[t & 15] = wt;
}
ap_uint<32> S1 = rotr(e, 6) ^ rotr(e, 11) ^ rotr(e, 25);
ap_uint<32> ch = (e & f) ^ ((~e) & g);
ap_uint<32> temp1 = h + S1 + ch + K[t] + wt;
ap_uint<32> S0 = rotr(a, 2) ^ rotr(a, 13) ^ rotr(a, 22);
ap_uint<32> maj = (a & b) ^ (a & c) ^ (b & c);
ap_uint<32> temp2 = S0 + maj;
h = g;
g = f;
f = e;
e = d + temp1;
d = c;
c = b;
b = a;
a = temp1 + temp2;
}
out.h[0] = 0x6a09e667 + a;
out.h[1] = 0xbb67ae85 + b;
out.h[2] = 0x3c6ef372 + c;
out.h[3] = 0xa54ff53a + d;
out.h[4] = 0x510e527f + e;
out.h[5] = 0x9b05688c + f;
out.h[6] = 0x1f83d9ab + g;
out.h[7] = 0x5be0cd19 + h;
}
static void sha256d_oneblock(const ap_uint<32> in_block[16], digest256_t &out) {
#pragma HLS INLINE off
digest256_t mid;
ap_uint<32> block2[16];
#pragma HLS ARRAY_PARTITION variable=block2 complete
sha256_compress(in_block, mid);
for (int i = 0; i < 8; i++) {
#pragma HLS UNROLL
block2[i] = mid.h[i];
}
block2[8] = 0x80000000;
block2[9] = 0;
block2[10] = 0;
block2[11] = 0;
block2[12] = 0;
block2[13] = 0;
block2[14] = 0;
block2[15] = 256; // 32 bytes = 256 bits
sha256_compress(block2, out);
}
extern "C" {
void sha256d_axis(hls::stream<axis32_t> &s_in,
hls::stream<axis32_t> &s_out,
int num_blocks) {
#pragma HLS INTERFACE axis port=s_in
#pragma HLS INTERFACE axis port=s_out
#pragma HLS INTERFACE s_axilite port=num_blocks bundle=CTRL
#pragma HLS INTERFACE s_axilite port=return bundle=CTRL
for (int blk = 0; blk < num_blocks; blk++) {
ap_uint<32> block[16];
#pragma HLS ARRAY_PARTITION variable=block complete
digest256_t out;
for (int i = 0; i < 16; i++) {
#pragma HLS PIPELINE II=1
axis32_t v = s_in.read();
block[i] = v.data;
}
sha256d_oneblock(block, out);
for (int i = 0; i < 8; i++) {
#pragma HLS PIPELINE II=1
axis32_t v;
v.data = out.h[i];
v.keep = -1;
v.strb = -1;
v.last = ((blk == num_blocks - 1) && (i == 7)) ? 1 : 0;
s_out.write(v);
}
}
}
}
テストベンチ
#include <iostream>
#include <iomanip>
#include "ap_axi_sdata.h"
#include "hls_stream.h"
typedef ap_axiu<32, 0, 0, 0> axis32_t;
extern "C" {
void sha256d_axis(hls::stream<axis32_t> &s_in,
hls::stream<axis32_t> &s_out,
int num_blocks);
}
static void make_padded_abc(unsigned int block[16]) {
unsigned char msg[64] = {0};
msg[0] = 'a';
msg[1] = 'b';
msg[2] = 'c';
msg[3] = 0x80;
msg[63] = 24; // 3 bytes * 8 bits
for (int i = 0; i < 16; i++) {
block[i] =
((unsigned int)msg[4*i + 0] << 24) |
((unsigned int)msg[4*i + 1] << 16) |
((unsigned int)msg[4*i + 2] << 8) |
((unsigned int)msg[4*i + 3] << 0);
}
}
int main() {
hls::stream<axis32_t> s_in;
hls::stream<axis32_t> s_out;
unsigned int block[16];
make_padded_abc(block);
for (int i = 0; i < 16; i++) {
axis32_t v;
v.data = block[i];
v.keep = -1;
v.strb = -1;
v.last = (i == 15) ? 1 : 0;
s_in.write(v);
}
sha256d_axis(s_in, s_out, 1);
std::cout << "digest = ";
for (int i = 0; i < 8; i++) {
axis32_t v = s_out.read();
std::cout << std::hex
<< std::setw(8)
<< std::setfill('0')
<< (unsigned int)v.data;
}
std::cout << std::endl;
return 0;
}
プラグマのコツ
SHA256dの解説は置いておき、主に#pragma HLSの使い方について記す。
C/C++のまま書くと、Vitisでは正しい回路を作ろうとはするが、性能や資源の使い方は必ずしも狙い通りにならない。
そこでVitisのみで指示できる、
INLINE, UNROLL, PIPELINE, ARRAY_PARTITION, INTERFACEを使い、
レイテンシとスループットのバランスを制御している。
例えば、ローテンション関数には#pragma HLS INLINEを付けている。
static inline ap_uint<32> rotr(ap_uint<32> x, int n) {
#pragma HLS INLINE
return (x >> n) | (x << (32 - n));
}
これは、この関数を独立したハードウェアブロックとして残すのではなく、呼び出し元に展開してほしいという指示である。 rotr() は 32 ビットのローテートという非常に小さい処理であり、ここを関数呼び出しの境界として残すメリットはほぼない。むしろインライン化しておいた方が、SHA-256 のラウンド演算の中に自然に溶け込み、余計な制御回路を作らずに済む。
一方で、sha256_compress() と sha256d_oneblock()には#pragma HLS INLINE offを付けている。
static void sha256_compress(const ap_uint<32> block[16], digest256_t &out) {
#pragma HLS INLINE off
ここは逆に、大きな処理単位として保持したいためである。
SHA256で用いる定数テーブルにはARRAY_PARTITION completeをつけている。
これは、64要素の配列をそのままRAMとして持つのではなく、全要素を完全分割して並列アクセス可能にする指示である。
SHA-256の各ラウンドではK[t]を毎サイクル参照する。ここでKが単ポートRAMのように実装されると、読み出し制約がパイプラインの障害になる可能性がある。completeを付けることで、各要素を個別の定数として持つ形になり、ラウンドごとの参照が軽くなる。
簡単に言うと、メモリ扱いせずレジスタとして展開させたいだけである。
16ワードのコピーするループにはUNROLLを付けている。
for (int i = 0; i < 16; i++) {
#pragma HLS UNROLL
W[i] = block[i];
}
UNROLL はループを展開し、16回の代入を並列化する指示である。
これにより、1要素ずつ、16サイクルかけて初期化するのではなく、合成上は16本の代入として同時に処理される。
SHA-256の本体である、64ラウンドのループには、PIPELINE II=1を付けている。
for (int t = 0; t < 64; t++) {
#pragma HLS PIPELINE II=1
...
}
パイプライン処理はFPGAの醍醐味でもあり、1クロックごとに次のラウンドを投入できるようにしたいという意味である。
トップ関数sha256d_axis()では、インタフェース指定のpragmaが並んでいる。
#pragma HLS INTERFACE axis port=s_in
#pragma HLS INTERFACE axis port=s_out
#pragma HLS INTERFACE s_axilite port=num_blocks bundle=CTRL
#pragma HLS INTERFACE s_axilite port=return bundle=CTRL
s_inとs_outはaxis指定なので、データ本体はAXI4-Streamで入出力される。
それ以外は制御レジスタ用のAXI4-Liteを指定した。
テストベンチとCシミュレーション
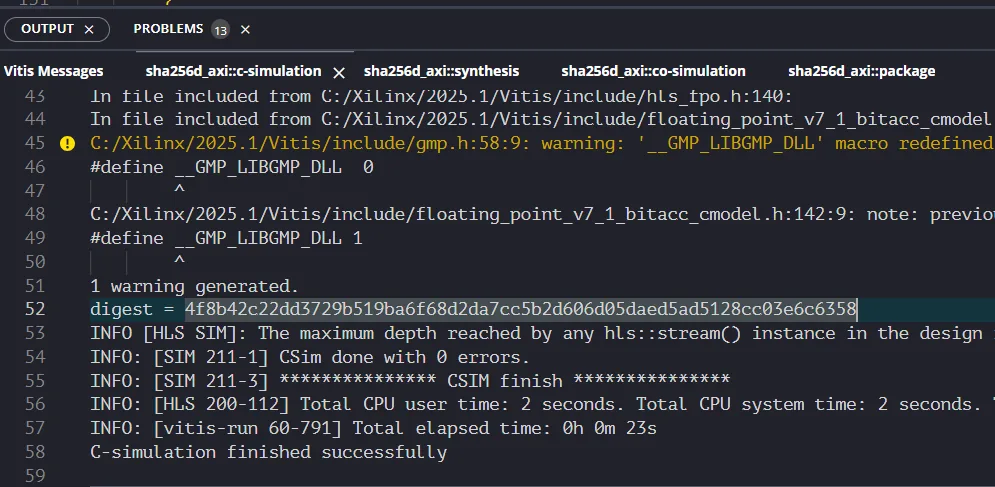
テストベンチには簡単なSHA256dを実施したいメッセージを記述しただけである。
実際に実行すると、目的のハッシュ値が得られた。
合成
次に合成を行う。
ここでは設定したクロック周波数で動作するか、リソース数を大まかな検証を行うことができる。
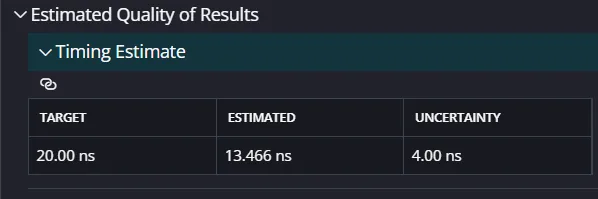
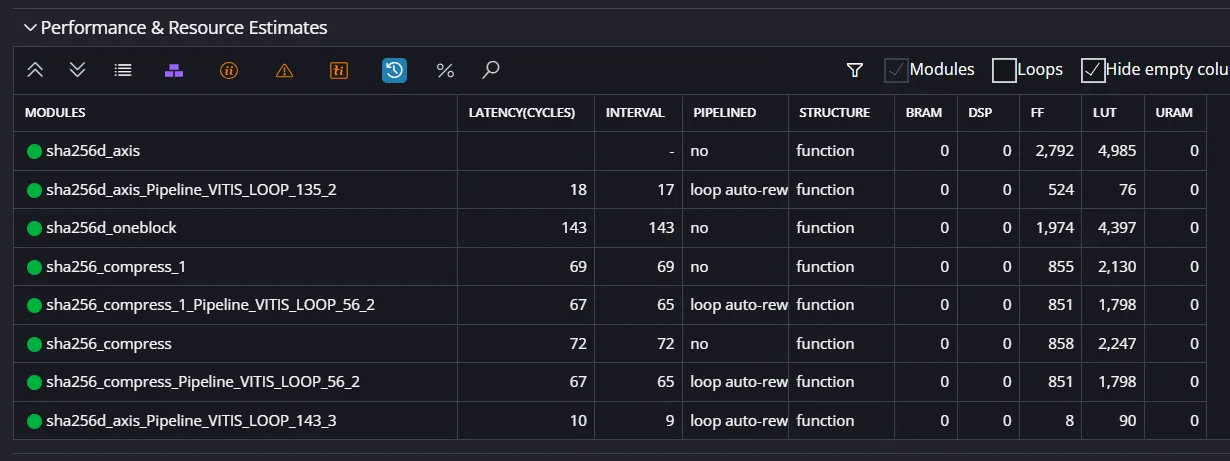
ちなみに当初、100MHz(±20%)で合成したところ、SLACKが-5.47となり、合成できなかったため、50MHzにクロックダウンした。
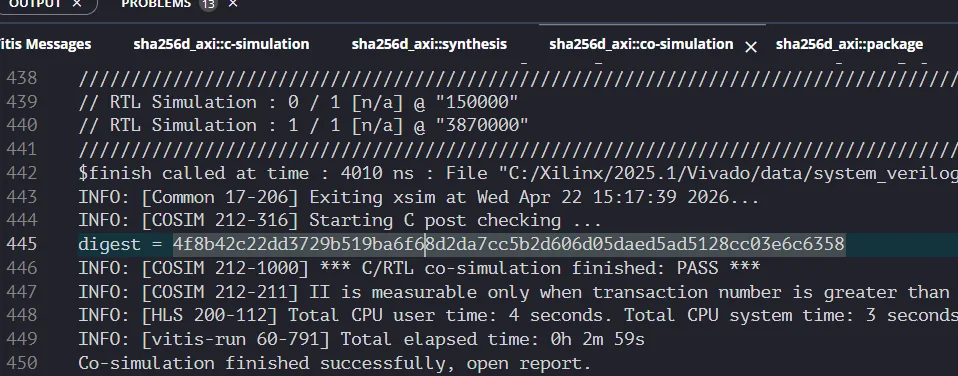
C/RTL Coシミュレーション
実際に合成したRTLを用いて、Cで書いたテストベンチを検証しているとのこと。
正しいハッシュ値が出ている。
IP生成
高位合成で生成したモノはIPとして、zipファイルとして出力される。
Vivadoでの作業
HDLをゴリゴリ書く、といったことはせず、ブロック図を並べるだけである。
はじめに高位合成で生成したIPをVivadoで利用できるようにする。
ブロックダイアグラムエディタ
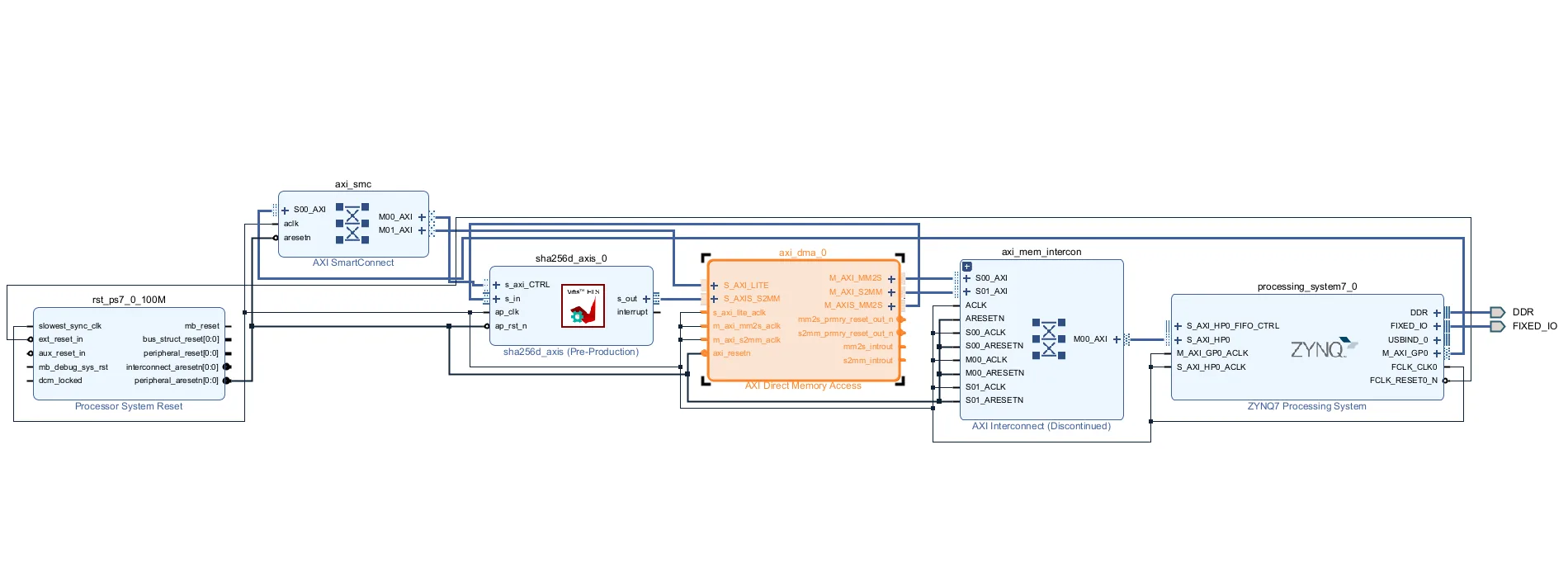
制御を行うZynq(PS)を配置し、自動的に配線を行ったあとに、SHA256dのIPを配置する。
今回はDMAを利用しているため、AXI DMAも配置した。
PLクロックの設定

AXI HPバスを有効化する
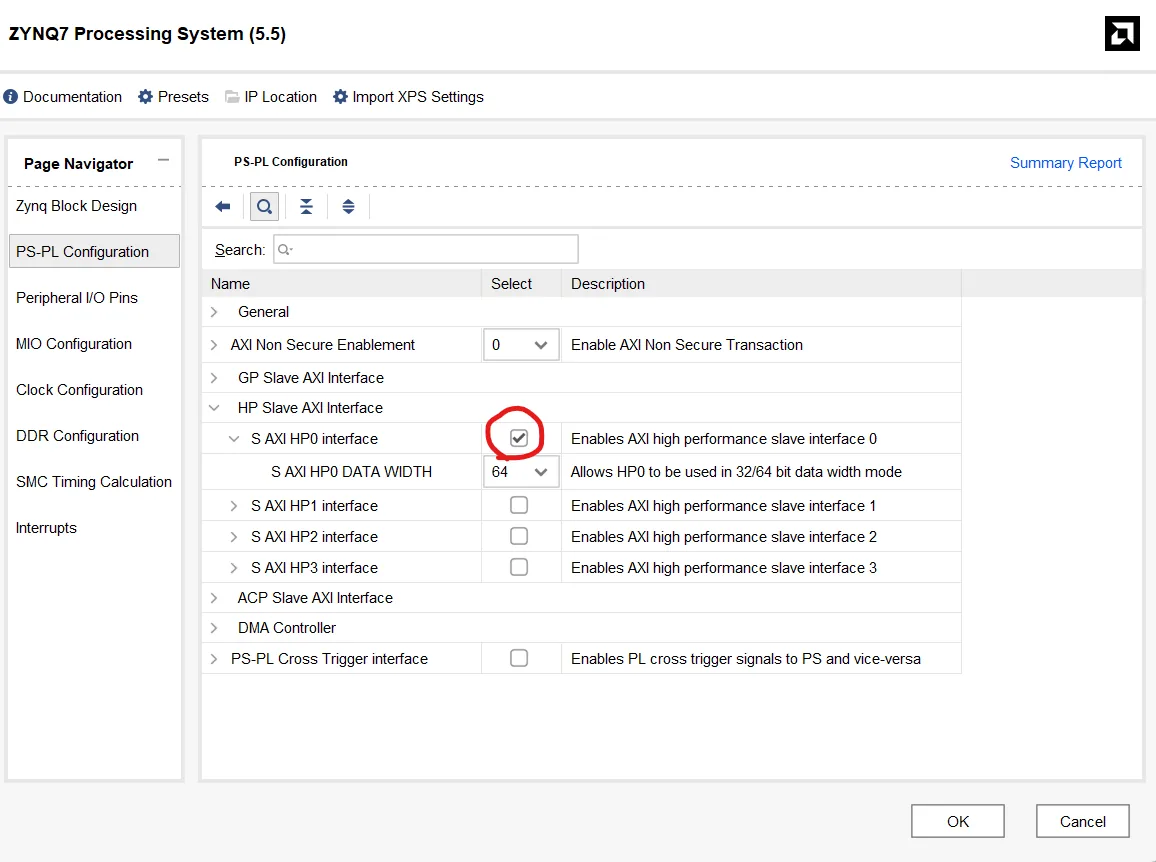
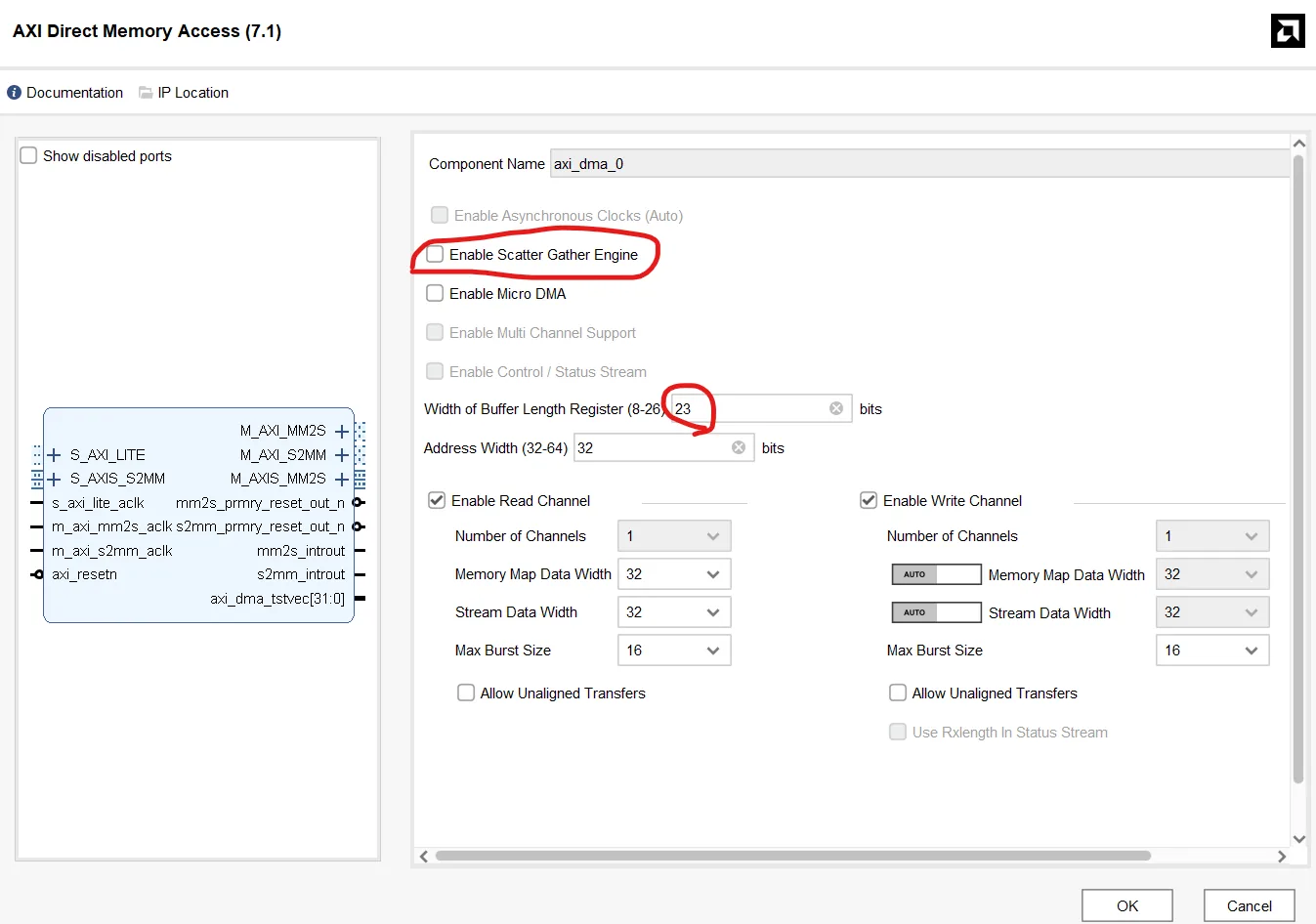
DMAの設定 簡素化&高性能化を図るため、Scatter Gatherを無効化、
Width of Bufferを14から23bitに拡張した。
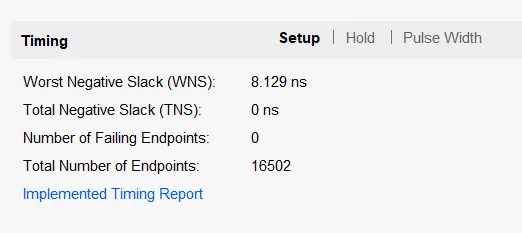
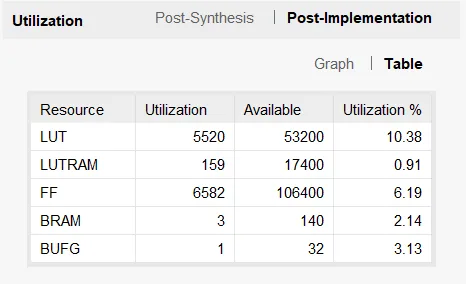
これでValidate、HDL Wapperの追加を行い、Bitstreamを生成する。
5分程度で完了した。
実際に利用されるリソース数などが表示された。
プラットフォームを用いたCでの開発ではVivadoからExportする必要があるが、Pynqでは不要である。
実際に使用するファイルは.bitファイルと.hwhファイルの2つである。
それぞれ、プロジェクトフォルダの以下のパスに生成されていた。
vivado\260422_sha256d_zynq\260422_sha256d_zynq.runs\impl_1\
sha256d.bit
vivado\260422_sha256d_zynq\260422_sha256d_zynq.gen\sources_1\bd\design_1\
hw_handoff\sha256d.hwh
Jupyter Notebookでの検証
.bitファイルと.hwhファイルをアップロードしておく。
そのファイルと同じ階層にNotebookファイルを作成し、以下のようなPythonコードを記述した。
単一のメッセージをSHA256d
from pynq import Overlay, allocate
import numpy as np
import hashlib
ol = Overlay("./sha256d.bit")
dma = ol.axi_dma_0
ip = ol.sha256d_axis_0
def pad_oneblock(msg: bytes) -> np.ndarray:
assert len(msg) <= 55
buf = bytearray(64)
buf[:len(msg)] = msg
buf[len(msg)] = 0x80
buf[56:64] = (len(msg) * 8).to_bytes(8, "big")
return np.frombuffer(buf, dtype=">u4").astype(np.uint32)
msgs = [b"abc", b"hello", b"pynq"]
n = len(msgs)
in_buf = allocate(shape=(n, 16), dtype=np.uint32)
out_buf = allocate(shape=(n, 8), dtype=np.uint32)
for i, m in enumerate(msgs):
in_buf[i] = pad_oneblock(m)
# 念のためキャッシュ反映
in_buf.flush()
# HLS引数
ip.write(0x10, n)
# DMA転送開始
dma.recvchannel.transfer(out_buf)
dma.sendchannel.transfer(in_buf)
# HLS開始
ip.write(0x00, 0x01)
dma.sendchannel.wait()
dma.recvchannel.wait()
# 念のためキャッシュ無効化
out_buf.invalidate()
for i, m in enumerate(msgs):
hw = out_buf[i].astype(">u4").tobytes().hex()
sw = hashlib.sha256(hashlib.sha256(m).digest()).hexdigest()
print(m, hw, sw, hw == sw)
実行結果

(すごく簡単に書いていますが、何度もHLSに戻り、Vivadoで再合成して、Pynqで再検証を繰り返しています…)
PS側でのハッシュと比較する
今回実装したSHA256dアクセラレータの有効性を評価するため、PS(ARM CPU)によるソフトウェア実装と、PL(FPGA)によるハードウェア実装のハッシュレートを比較した。
比較は同一環境(PYNQ-Z2)上で行い、同一の入力データを4096件まとめて処理することで測定した。
PS側はPythonのhashlibを用いたSHA256d、PL側はAXI DMAを介してHLS実装のSHA256dコアを実行する構成である。
実際に利用したPythonソース
from pynq import Overlay, allocate
import numpy as np
import hashlib
import time
ol = Overlay("./sha256d.bit", download=True)
ip = ol.sha256d_axis_0
dma = ol.axi_dma_0
# PYNQ側のDMAメタデータ問題の回避
dma.sendchannel._max_size = (1 << 23) - 1
dma.recvchannel._max_size = (1 << 23) - 1
def pad_oneblock(msg: bytes) -> np.ndarray:
assert len(msg) <= 55
buf = bytearray(64)
buf[:len(msg)] = msg
buf[len(msg)] = 0x80
buf[56:64] = (len(msg) * 8).to_bytes(8, "big")
return np.frombuffer(buf, dtype=">u4").astype(np.uint32)
def bench_pl(msg: bytes, num=4096, repeat=5):
blk = pad_oneblock(msg)
in_buf = allocate(shape=(num, 16), dtype=np.uint32)
out_buf = allocate(shape=(num, 8), dtype=np.uint32)
for i in range(num):
in_buf[i] = blk
in_buf.flush()
# warm-up
ip.write(0x10, num)
dma.recvchannel.transfer(out_buf)
dma.sendchannel.transfer(in_buf)
ip.write(0x00, 0x01)
dma.sendchannel.wait()
dma.recvchannel.wait()
out_buf.invalidate()
times = []
for _ in range(repeat):
in_buf.flush()
ip.write(0x10, num)
t0 = time.perf_counter()
dma.recvchannel.transfer(out_buf)
dma.sendchannel.transfer(in_buf)
ip.write(0x00, 0x01)
dma.sendchannel.wait()
dma.recvchannel.wait()
t1 = time.perf_counter()
out_buf.invalidate()
times.append(t1 - t0)
digest0 = out_buf[0].astype(">u4").tobytes().hex()
in_buf.close()
out_buf.close()
return {
"digest": digest0,
"times": times,
"avg_hps": num / (sum(times) / len(times)),
"best_hps": num / min(times),
}
def sha256d_sw(msg: bytes) -> bytes:
return hashlib.sha256(hashlib.sha256(msg).digest()).digest()
def bench_ps_hashlib(msg: bytes, num=4096, repeat=5):
# warm-up
ref = sha256d_sw(msg)
times = []
for _ in range(repeat):
t0 = time.perf_counter()
for _ in range(num):
sha256d_sw(msg)
t1 = time.perf_counter()
times.append(t1 - t0)
return {
"digest": ref.hex(),
"times": times,
"avg_hps": num / (sum(times) / len(times)),
"best_hps": num / min(times),
}
msg = b"abc"
pl = bench_pl(msg, num=4096, repeat=5)
ps = bench_ps_hashlib(msg, num=4096, repeat=5)
print("PL digest :", pl["digest"])
print("PS digest :", ps["digest"])
print("match :", pl["digest"] == ps["digest"])
print()
print("PL times :", pl["times"])
print("PL avg :", pl["avg_hps"], "hashes/s")
print("PL best :", pl["best_hps"], "hashes/s")
print()
print("PS times :", ps["times"])
print("PS avg :", ps["avg_hps"], "hashes/s")
print("PS best :", ps["best_hps"], "hashes/s")
print()
print("speedup(avg) =", pl["avg_hps"] / ps["avg_hps"])
print("speedup(best) =", pl["best_hps"] / ps["best_hps"])
実行結果
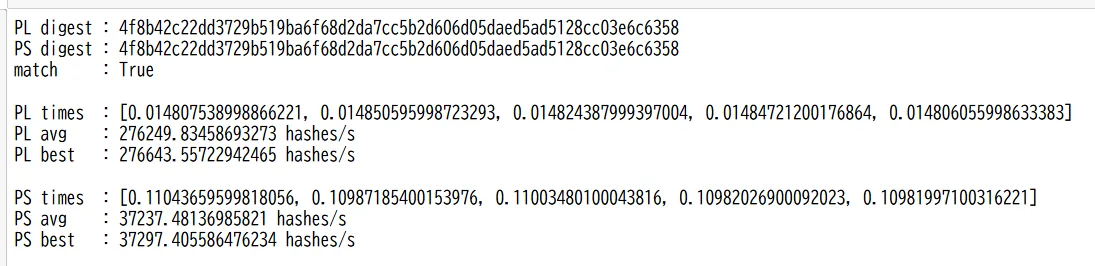
| 指標 | PL (FPGA) | PS (CPU) |
|---|---|---|
| 平均ハッシュレート | 276,249.83 H/s | 37,237.48 H/s |
| 最大ハッシュレート | 276,643.56 H/s | 37,297.41 H/s |
この結果から、PLによるハードウェア実装はPSのソフトウェア実装に対して、約7.4倍の高速化を達成していることが確認できる。
なお、PL側の測定は4096件のデータを1回のDMA転送で処理する「1-shot転送」としており、DMA起動やPythonからの制御に伴うオーバーヘッドは含まれている。
そのため、この値は純粋なFPGA単体の性能ではなく、実際のアプリケーションに近い性能である。
PS側のhashlibはOpenSSLベースの最適化されたC実装であり、CPU上でも十分に高速である。それにもかかわらず約7倍の差が確認できたことから、この差は実装言語の違いではなく、FPGAにおけるパイプライン化(II=1)された専用回路によるスループット最適化の効果によるものと考えられる。
まとめ
今回の実装は単一コア・50MHz動作であり、まだリソース的な余裕がある。
したがって、コアの並列化やクロック向上を行うことで、さらなるスループット向上が見込まれる。
特にBitcoinマイニング用途を考える場合には、SHA256dの処理構造を特化させた設計(midstateの利用など)により、より大きな性能向上が期待できる。
次回以降、並列化とマイニング向け最適化を行う。