概要
本シリーズでは、楕円曲線暗号でのスカラー倍算を、Zynq FPGA上に高位合成(HLS)で実装する。
Part1では、その中でも最も支配的な演算である、256bit乗算に焦点を当てる。
乗算の重要性
楕円曲線スカラー倍算では以下のような構造を持つ。
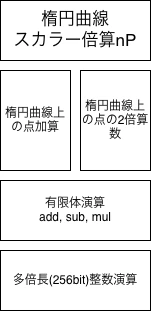
点加算や2倍算では乗算が複数回発生し、各ステップは前ステップの結果に依存する。
比率としては、乗算が圧倒的に多く、次いで加減算で構成される。
このことから、楕円曲線暗号では剰余乗算が支配的な処理となっており、楕円曲線研究者は日々、乗算を減らしたり、剰余乗算の高速化の研究を行っている。
設計方針
点加算では並列化は難しいため、一つの乗算器を高速化して使い回す方針で設計する。
評価対象
256bit乗算を以下の構成で実装した。
- 32bit分割(逐次)
- 64bit分割(逐次)
- 128bit分割(逐次)
- DSP最適分割(25×18)
- HLS直接乗算(256bit direct)
32bitや64bitは実際の暗号ライブラリでも用いられている多倍長整数のワードサイズであり、移植性が高い。
128bit分割はC++で対応している場合もあるが、HLSではap_uint<128>型を用いて128bit変数が利用可能となる。
ap_uint型を用いて256bitを直接乗算する方法でも実験した。
また、個人的に気になったものとして、DSPの乗算器にフィットしたサイズでも実験してみる。
ZynqのFPGAに搭載されているDSP48E1は、25bit×18bitの乗算器が搭載されており、それに合わせたワードでの実装も検証した。
環境
- FPGAボード PYNQ-Z2
- FPGA ZYNQ XC7Z020-1CLG400C
- HLSツール Vitis 2025.01
各種実装方式のレイテンシやリソース数はVitisでの高位合成時の結果である。
高位合成に用いたソース
先頭にap_int.hを宣言した
#include <ap_int.h>
typedef ap_uint<256> uint256_t;
typedef ap_uint<512> uint512_t;
32×32逐次
#define LIMBS32 8
static ap_uint<32> get_limb32(uint256_t x, int i) {
#pragma HLS INLINE
return x.range(i * 32 + 31, i * 32);
}
uint512_t mul256_32x32(uint256_t a, uint256_t b) {
#pragma HLS PIPELINE II=1
ap_uint<32> a_limb[LIMBS32];
ap_uint<32> b_limb[LIMBS32];
#pragma HLS ARRAY_PARTITION variable=a_limb complete
#pragma HLS ARRAY_PARTITION variable=b_limb complete
for (int i = 0; i < LIMBS32; i++) {
#pragma HLS UNROLL
a_limb[i] = get_limb32(a, i);
}
for (int j = 0; j < LIMBS32; j++) {
#pragma HLS UNROLL
b_limb[j] = get_limb32(b, j);
}
uint512_t acc = 0;
for (int i = 0; i < LIMBS32; i++) {
#pragma HLS UNROLL
for (int j = 0; j < LIMBS32; j++) {
#pragma HLS UNROLL
ap_uint<64> p;
#pragma HLS BIND_OP variable=p op=mul impl=dsp
p = a_limb[i] * b_limb[j];
acc += ((uint512_t)p << ((i + j) * 32));
}
}
return acc;
}
64×64逐次
static ap_uint<64> get_limb64(uint256_t x, int i) {
#pragma HLS INLINE
return x.range(i * 64 + 63, i * 64);
}
uint512_t mul256_64x64(uint256_t a, uint256_t b) {
#pragma HLS PIPELINE II=1
ap_uint<64> a_limb[4];
ap_uint<64> b_limb[4];
#pragma HLS ARRAY_PARTITION variable=a_limb complete
#pragma HLS ARRAY_PARTITION variable=b_limb complete
for (int i = 0; i < 4; i++) {
#pragma HLS UNROLL
a_limb[i] = get_limb64(a, i);
}
for (int j = 0; j < 4; j++) {
#pragma HLS UNROLL
b_limb[j] = get_limb64(b, j);
}
uint512_t acc = 0;
for (int i = 0; i < 4; i++) {
#pragma HLS UNROLL
for (int j = 0; j < 4; j++) {
#pragma HLS UNROLL
ap_uint<128> p;
#pragma HLS BIND_OP variable=p op=mul impl=dsp
p = a_limb[i] * b_limb[j];
acc += ((uint512_t)p << ((i + j) * 64));
}
}
return acc;
}
128×128逐次
static ap_uint<128> get_limb128(uint256_t x, int i) {
#pragma HLS INLINE
return x.range(i * 128 + 127, i * 128);
}
uint512_t mul256_128x128(uint256_t a, uint256_t b) {
#pragma HLS PIPELINE II=1
ap_uint<128> a_limb[2];
ap_uint<128> b_limb[2];
#pragma HLS ARRAY_PARTITION variable=a_limb complete
#pragma HLS ARRAY_PARTITION variable=b_limb complete
for (int i = 0; i < 2; i++) {
#pragma HLS UNROLL
a_limb[i] = get_limb128(a, i);
}
for (int j = 0; j < 2; j++) {
#pragma HLS UNROLL
b_limb[j] = get_limb128(b, j);
}
uint512_t acc = 0;
for (int i = 0; i < 2; i++) {
#pragma HLS UNROLL
for (int j = 0; j < 2; j++) {
#pragma HLS UNROLL
ap_uint<256> p;
#pragma HLS BIND_OP variable=p op=mul impl=dsp
p = a_limb[i] * b_limb[j];
acc += ((uint512_t)p << ((i + j) * 128));
}
}
return acc;
}
DSP最適分割(25×18)
uint512_t mul256_dsp25x18(uint256_t a, uint256_t b) {
#pragma HLS PIPELINE off
ap_uint<25> a_limb[A_LIMBS];
ap_uint<18> b_limb[B_LIMBS];
#pragma HLS ARRAY_PARTITION variable=a_limb complete
#pragma HLS ARRAY_PARTITION variable=b_limb complete
for (int i = 0; i < A_LIMBS; i++) {
#pragma HLS UNROLL
a_limb[i] = get_limb25(a, i);
}
for (int j = 0; j < B_LIMBS; j++) {
#pragma HLS UNROLL
b_limb[j] = get_limb18(b, j);
}
uint512_t acc = 0;
for (int i = 0; i < A_LIMBS; i++) {
uint512_t row = 0;
for (int j = 0; j < B_LIMBS; j++) {
#pragma HLS UNROLL
ap_uint<43> p;
#pragma HLS BIND_OP variable=p op=mul impl=dsp
p = a_limb[i] * b_limb[j];
const int shift = i * 25 + j * 18;
row += ((uint512_t)p << shift);
}
acc += row;
}
return acc;
}
256bit direct
uint512_t mul256_direct(uint256_t a, uint256_t b) {
#pragma HLS PIPELINE II=1
uint512_t c;
#pragma HLS BIND_OP variable=c op=mul impl=dsp
c = (uint512_t)a * (uint512_t)b;
return c;
}
比較結果
| 実装方式 | レイテンシ[cc] | DSP | FF | LUT |
|---|---|---|---|---|
| 32×32逐次 | 65 | 4 | 1,995 | 2,661 |
| 64×64逐次 | 17 | 16 | 1,983 | 2,602 |
| 128×128逐次 | 10 | 63 | 2,298 | 2,845 |
| DSP最適分割(25×18) | 22 | 15 | 15,961 | 28,447 |
| 256bit direct | 1 | 225 | 36 | 49 |
考察
今回の結果は分割サイズでレイテンシやリソース数がきれいに変化した。
分割サイズを増加させるとDSPの数が増え、レイテンシが改善する。
FFやLUTの数はそこまで大きく変化しない。
特に128bit分割はDSPの使用リソース率が30%程度で10[cc]とリソース数と速度のバランスが良く、この実装を用いたい。
256bit変数を用いた乗算は非常に高速であり、FFやLUTが非常に少なくなっているが、DSPの使用率がこのFPGAではオーバーしているため、実装が不可能である。
DSP48E1の乗算幅に合わせた25×18分割も試したが、今回の用途では最適とはならなかった。
25×18分割はDSPの基本乗算幅には合っているものの、256bit乗算全体として見ると部分積数が増え、加算ネットワークが大きくなる。
結果として、15個DSPでもFFが15961、LUTが28447となり、他の逐次構成よりロジック使用量が大きくなった。
128bit分割での256mulをFPGAで動かす
上記の考察で128bit分割での乗算器を実装することにした。
いつも通りのVitisでIP化して、vivadoでZynqと乗算IPを配置配線し、Bitstream生成して、PYNQで動かす。

bitstream後の合成結果
WNSとTNSが怪しいがとりあえずやってみる。

jupyter notebookでの作業
from pynq import Overlay
from pynq import MMIO
ol = Overlay("mul256_128limb.bit")
ol.ip_dict
ip = ol.mul256_top_0
mmio = ip.mmio
def write_u256(base, x):
for i in range(8):
mmio.write(base + i*4, (x >> (32*i)) & 0xffffffff)
def read_u512(base):
x = 0
for i in range(16):
w = mmio.read(base + i*4)
x |= w << (32*i)
return x
CTRL = 0x00
A_BASE = 0x10
B_BASE = 0x34
C_BASE = 0x58
a = 0x123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef
b = 0xfedcba9876543210fedcba9876543210fedcba9876543210fedcba9876543210
# 入力書き込み
write_u256(A_BASE, a)
write_u256(B_BASE, b)
# 開始
mmio.write(CTRL, 0x01)
# 完了待ち
while (mmio.read(CTRL) & 0x2) == 0:
pass
# 結果取得
hw = read_u512(C_BASE)
sw = a * b
print("HW:", hex(hw))
print("SW:", hex(sw))
print("OK:", hw == sw)

Pythonでの演算と一致している。
次回
Part2では剰余の実装を行う。
今回はビットコインでも用いられているsecp256k1で実装を行いたいので、このパラメータに適した剰余の計算法での剰余乗算を実装する。
ついでに剰余の加減算も実装し、有限体演算を完成させたい。