概要
Part1では楕円曲線スカラー倍算に必要な多倍長整数乗算器について検証を行った。
本稿ではその中核となる256bit有限体演算、すなわち剰余加算・減算・乗算器を高位合成(HLS)で実装し、その性能とリソース特性を評価する。
対象とする曲線は
secp256k1
であり、有限体の法は
p = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F
である。
これはビット列的にきれいな形であり、
$ p = 2^{256} - 2^{32} - 977 $
という特徴的な形状を持つ。
この構造をどこまで活用できるかが、回路効率を大きく左右する。
剰余加算の実装
有限体の加算は足し算と余りの計算で構成され、
$(a + b) \bmod p$
であるが、HLSではこの記述方法がそのまま回路構造に反映される。
剰余記号(%)を用いた実装
一般的にプログラミングで余りを求める際に剰余記号%を用いることが多いと思う。
基本的に除算を行って余りを求めるため、計算コストが非常に高い。
そのため、暗号ライブラリでは用いられていない。
しかし、「もしかしたらAMDさんが最適な剰余を求める回路を作ってくれるかもしれない」という僅かな望みにかけて、試してみた。
r = (a + b) % P;
条件付き減算による実装
有限体の性質として、
$a, b < p \Rightarrow a + b < 2p$
が成り立つ。したがって、
$t = a + b$ を行い、桁溢れが発生したとき、 $t - p$
で除算を使わずに剰余加算が実装できる。
実装例
一時的に桁溢れで257bitになるため、uint257_t変数を用意する。
uint257_t t = (uint257_t)a + (uint257_t)b;
uint257_t t_minus_p = t - (uint257_t)P;
if (t >= (uint257_t)P)
r = t_minus_p;
else
r = t;
結果
結果としては、一般的な除算を行ってからの剰余を行っているようなレイテンシとリソース数になってしまった。
| 実装 | Latency | FF | LUT | DSP |
|---|---|---|---|---|
剰余記号% 版 | 263 cycle | 2,695 | 3,580 | 0 |
| 条件付き減算版 | 3 cycle | 3,395 | 2,380 | 0 |
剰余記号版のレイテンシは263[cc]と、除算回路を生成しているようなレイテンシとなっている。
条件付き減算版では3[cc]と約87倍程度高速になっている。
使用リソース数もそこまで大きな変化はなく、高速化できるため、普通に暗号ライブラリで用いられている方法を実装したほうがいい。
mulmodの設計
乗算では256bit×256bitの結果が512bitとなるため、reduction(剰余)が支配的となる。
secp256k1の素数構造
$$ p = 2^{256} - 2^{32} - 977 $$
より
$$ 2^{256} \equiv 2^{32} + 977 \pmod{p} $$
が成り立つ。このため512bit値を
$$ x = lo + 2^{256} \cdot hi $$
と分解すると、
$$ x \equiv lo + hi \cdot (2^{32} + 977) $$
となる。
この性質により、除算を使わずにreductionが可能となる。
具体例
512bit値のうち bit 256だけが立っている値を考える。
この512bitを256bitに分割すると、下位256bit[255:0]がすべて0で、上位256bit[511:256]の最下位bitだけが1である。
x = 512bit value
hi = 000...0001
lo = 000...0000
通常の2進表現では、この hi の1bitは
1 << 256
を意味する。しかし secp256k1 の法
$$ p = 2^{256} - 2^{32} - 977 $$
では、
$$ 2^{256} \equiv 2^{32} + 977 \pmod{p} $$
なので、bit 256にある 1 は、有限体上では下位側へ次のように折り返せる。
1 << 256
≡ (1 << 32) + 977
10進数の977は、2進数では
0b11 1101 0001
である。つまり、bit位置で見ると
977 = 2^9 + 2^8 + 2^7 + 2^6 + 2^4 + 2^0
となる。
したがって、
2^256
≡ 2^32 + 2^9 + 2^8 + 2^7 + 2^6 + 2^4 + 2^0
である。
ビット列としては、512bit中の bit 256 にあった1が、reduction後には下位256bit内の bit 32, 9, 8, 7, 6, 4, 0 に折り返されるイメージである。
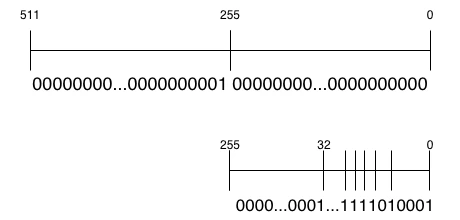
512bit乗算結果の上位256bitを、下位側へ「折り返す」ことで剰余を計算できる。このため、一般的な除算器を使わずに、シフトと加算を中心としたreductionが可能になる。
なお、このような疑メルセンヌ素数を用いたreductionは、Bitcoin Coreのsecp256k1実装でも採用されている。
https://github.com/bitcoin-core/secp256k1/blob/b11340b3ce2afac1b6ffda4ce5828c30621d2917/src/field_5x52_impl.h#L43
実装
HLSではこの折り返し処理を複数段に分けて実装する。
uint256_t lo = x.range(255, 0);
uint256_t hi = x.range(511, 256);
t = lo + (hi << 32) + mul977(hi);
これを数回繰り返し、最後に条件付き減算で正規化する。
HLSソース
128bit乗算は前回の記事で合成したものを再利用。
#include <ap_int.h>
typedef ap_uint<256> uint256_t;
typedef ap_uint<512> uint512_t;
uint512_t mul256_128x128_serial(uint256_t a, uint256_t b);
static const uint256_t SECP256K1_P =
(((uint256_t)0xFFFFFFFFULL << 224) |
((uint256_t)0xFFFFFFFFULL << 192) |
((uint256_t)0xFFFFFFFFULL << 160) |
((uint256_t)0xFFFFFFFFULL << 128) |
((uint256_t)0xFFFFFFFFULL << 96) |
((uint256_t)0xFFFFFFFFULL << 64) |
((uint256_t)0xFFFFFFFEULL << 32) |
((uint256_t)0xFFFFFC2FULL));
static uint256_t sub_if_ge_p(ap_uint<288> x) {
#pragma HLS INLINE
ap_uint<288> p288 = SECP256K1_P;
ap_uint<288> r = x;
for (int i = 0; i < 3; i++) {
#pragma HLS UNROLL
if (r >= p288) {
r = r - p288;
}
}
return r.range(255, 0);
}
static ap_uint<266> mul977_256(ap_uint<256> x) {
#pragma HLS INLINE
return ((ap_uint<266>)x << 10)
- ((ap_uint<266>)x << 5)
- ((ap_uint<266>)x << 4)
+ (ap_uint<266>)x;
}
static ap_uint<299> mul977_289(ap_uint<289> x) {
#pragma HLS INLINE
return ((ap_uint<299>)x << 10)
- ((ap_uint<299>)x << 5)
- ((ap_uint<299>)x << 4)
+ (ap_uint<299>)x;
}
static ap_uint<76> mul977_66(ap_uint<66> x) {
#pragma HLS INLINE
return ((ap_uint<76>)x << 10)
- ((ap_uint<76>)x << 5)
- ((ap_uint<76>)x << 4)
+ (ap_uint<76>)x;
}
uint256_t secp256k1_reduce(uint512_t x) {
#pragma HLS PIPELINE II=1
uint256_t lo = x.range(255, 0);
uint256_t hi = x.range(511, 256);
// 1回目の折り返し
// x ≡ lo + hi * (2^32 + 977)
ap_uint<545> t;
t = (ap_uint<545>)lo
+ (((ap_uint<545>)hi) << 32)
+ mul977_256(hi);
ap_uint<256> t_lo = t.range(255, 0);
ap_uint<289> t_hi = t.range(544, 256);
// 2回目の折り返し
ap_uint<322> u;
u = (ap_uint<322>)t_lo
+ (((ap_uint<322>)t_hi) << 32)
+ mul977_289(t_hi);
ap_uint<256> u_lo = u.range(255, 0);
ap_uint<66> u_hi = u.range(321, 256);
// 3回目の折り返し
ap_uint<288> v;
v = (ap_uint<288>)u_lo
+ (((ap_uint<288>)u_hi) << 32)
+ mul977_66(u_hi);
return sub_if_ge_p(v);
}
uint256_t secp256k1_mul_mod(uint256_t a, uint256_t b) {
#pragma HLS PIPELINE off
uint512_t prod = mul256_128x128_serial(a, b);
return secp256k1_reduce(prod);
}
合成結果
最終構成
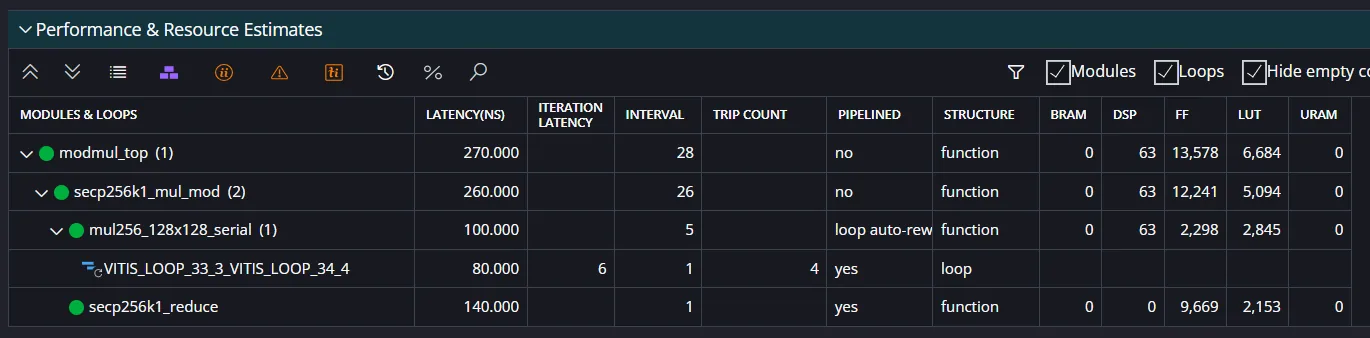
| Module | Latency | DSP | FF | LUT |
|---|---|---|---|---|
| modmul_top | 28 cycle | 63 | 13,578 | 6,684 |
このDSP 63はすべて128bit区切りの乗算器に由来する。
reductionは以下の通り完全にDSPを使用しない。
| Module | DSP | FF | LUT |
|---|---|---|---|
| secp256k1_reduce | 0 | 9,669 | 2,153 |
評価
PYNQ-Z2(Zynq-7020)におけるリソース使用率は以下の通り。
- DSP : 63 / 220 ≈ 29%
- LUT : 6.7k / 53k ≈ 13%
- FF : 13.6k / 106k ≈ 13%
DSPに余裕があるため、将来的に乗算器の並列化も可能である。
ECCスカラー倍算では乗算器がボトルネックとなるため、reductionでDSPを消費しない本構成は拡張性に優れている。
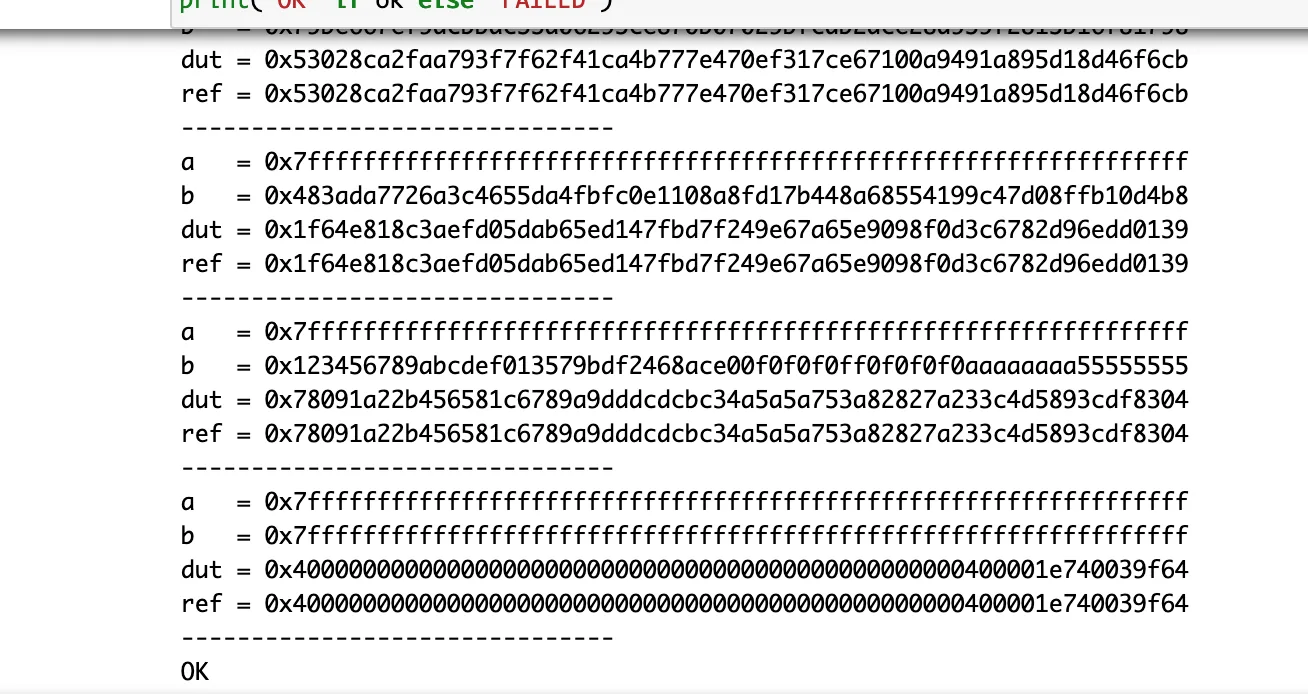
実機テスト
PYNQで適当な変数の剰余除算を行った。
python側で(a * b) % Pを行い、その値と比較する。
from pynq import Overlay
from time import perf_counter
ol = Overlay("design_1.bit")
ip = ol.modmul_top_0
P = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F
patterns = [
0, 1, 2, 3, 4, 5,
1 << 8,
1 << 16,
1 << 32,
1 << 64,
1 << 128,
1 << 192,
1 << 255,
P - 1,
P - 2,
P - 3,
P - 4,
P - 8,
P - 16,
P - 32,
P - 977,
P - 978,
P - 1024,
0x79BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798,
0x483ADA7726A3C4655DA4FBFC0E1108A8FD17B448A68554199C47D08FFB10D4B8,
0x123456789ABCDEF013579BDF2468ACE00F0F0F0FF0F0F0F0AAAAAAAA55555555,
0x7FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF,
]
CTRL = 0x00
A = 0x10
B = 0x34
C = 0x58
C_CTRL = 0x78
def write_u256(base, x):
x = int(x)
for i in range(8):
ip.write(base + 4*i, (x >> (32*i)) & 0xffffffff)
def read_u256(base):
x = 0
for i in range(8):
x |= int(ip.read(base + 4*i)) << (32*i)
return x
def modmul_hw(a, b):
write_u256(A, a)
write_u256(B, b)
ip.write(CTRL, 0x01)
while (ip.read(CTRL) & 0x2) == 0:
pass
return read_u256(C)
def modmul_py(a, b):
return (a * b) % P
ok = True
for a in patterns:
for b in patterns:
dut = modmul_hw(a, b)
ref = modmul_py(a, b)
print(f"a = 0x{a:064x}")
print(f"b = 0x{b:064x}")
print(f"dut = 0x{dut:064x}")
print(f"ref = 0x{ref:064x}")
print(f"-------------------------------")
if dut != ref:
print("Mismatch")
ok = False
break
if not ok:
break
print("OK" if ok else "FAILED")
まとめ
本稿では256bit有限体演算器をHLSで実装し、以下を確認した。
- 剰余加算では剰余記号
%を使うべきではない- 条件付き減算により約87倍の低レイテンシ化が可能
- secp256k1の素数構造により剰余はシフト加減算で実装可能
- 剰余モジュールのレイテンシは14[cc] (140[ns])であり、剰余記号だと263[cc]かかるため、圧倒的に有利
※再掲
| 実装 | Latency | FF | LUT | DSP |
|---|---|---|---|---|
| 剰余加算(条件分岐版) | 3 cycle | 3,395 | 2,380 | 0 |
| 剰余乗算 (シフト加減算) | 28 cycle | 13,578 | 6,684 | 63 |
HLSツールは最適な回路を出してくれることはなく、開発者はどのような回路に展開されるかを意識する必要がある。
次回はこれらの演算器を用いて、楕円曲線の点加算・倍算を実装し、スカラー倍算へと展開する。
あ、剰余減算忘れてたが、多分剰余加算とほとんど同じでしょう…
たぶんこんな感じ
if (a >= b) {
*r = a - b;
} else {
*r = (uint256_t)((uint257_t)a + (uint257_t)P - (uint257_t)b);
}