概要
前回の記事
では、64バイトの入力ブロックを受け取り、SHA256(SHA256(block))を計算する単純なSHA256dアクセラレータを実装していた。
しかし、実際のBTCマイニングでは、任意の64バイトメッセージに対するSHA256dを演算するのではなく、ブロックヘッダ(80バイト)を分割する必要がある。
そこで今回は、SHA256dアクセラレータをBitcoinマイニング向けに変更した。
具体的には、ブロックヘッダの第1チャンクをPS側で事前に処理してmidstateとしてPLへ渡し、PL側では第2チャンク、nonce、paddingを使ってSHA256dを計算する構成にした。
さらに、SHA-256の論理関数を関数化し、最後に1回目SHA-256の第2チャンク圧縮と2回目SHA-256圧縮をDataflow化した。
PYNQ-Z2上で実機検証した結果、最終的に約594kH/sを確認した。
前回は約276kH/sだったので、徐々に高速化している。
Bitcoinマイニング向けの入力形式
通常のSHA256d実装では、512-bit入力を受け取り、SHA256(SHA256(block))を求める。
一方、ビットコインのブロックヘッダは80バイトである。
そのため、SHA-256では次のように2チャンクに分かれる。
chunk 1: 64 bytes
┌──────────────────────────────────────────────────────────────┐
│ byte 0 63 │
│ <---------------------- 64 bytes --------------------------> │
└──────────────────────────────────────────────────────────────┘
chunk 2: 16 bytes + padding
┌──────────────┬──────┬──────────────────────────────┬─────────┐
│ 16 bytes msg │ 0x80 │ zero padding │ length │
│ │ │ │ 64-bit │
└──────────────┴──────┴──────────────────────────────┴─────────┘
一度chunk 1を処理すれば、nonceを変更する場合、chunk 1は再利用可能である。
https://crypto.stackexchange.com/questions/1862/how-can-i-calculate-the-sha-256-midstate
今回のHLS実装では、PLへの入力を次のようにした。
0..7 : midstate[0..7]
8 : w0 = merkle root tail
9 : w1 = time
10 : w2 = bits
11 : nonce_base
PL側(FPGA)ではnonce_baseからnum_nonces個のnonceを生成し、それぞれに対してSHA256dを計算する。
第2チャンクは以下のように構成した。
block1[0] = w0; // merkle root tail
block1[1] = w1; // time
block1[2] = w2; // bits
block1[3] = nonce; // nonce
block1[4] = 0x80000000;
block1[5] = 0;
...
block1[14] = 0;
block1[15] = 640; // 80 bytes * 8 bits
1回目のSHA-256では、初期値として標準IVではなく、PS側で計算済みのmidstateを使う。
その後、1回目SHA-256のdigestである first を32バイトメッセージとして、2回目のSHA-256を実行する。
block2[0..7] = first.h[0..7]
block2[8] = 0x80000000
block2[15] = 256
この構成により、PL側はnonce探索に必要な部分だけを処理するようになる。
ソースコード
static void sha256_compress_iv(
const ap_uint<32> block[16],
const digest256_t &iv,
digest256_t &out
) {
#pragma HLS INLINE off
static const ap_uint<32> K[64] = {
0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,
0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5,
0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,
0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174,
0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,
0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da,
0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,
0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967,
0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,
0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85,
0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,
0xd192e819,0xd6990624,0xf40e3585,0x106aa070,
0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,
0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3,
0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,
0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2
};
#pragma HLS ARRAY_PARTITION variable=K complete
ap_uint<32> W[16];
#pragma HLS ARRAY_PARTITION variable=W complete
ap_uint<32> a = iv.h[0];
ap_uint<32> b = iv.h[1];
ap_uint<32> c = iv.h[2];
ap_uint<32> d = iv.h[3];
ap_uint<32> e = iv.h[4];
ap_uint<32> f = iv.h[5];
ap_uint<32> g = iv.h[6];
ap_uint<32> h = iv.h[7];
for (int i = 0; i < 16; i++) {
#pragma HLS UNROLL
W[i] = block[i];
}
for (int t = 0; t < 64; t++) {
#pragma HLS PIPELINE II=1
ap_uint<32> wt;
if (t < 16) {
wt = W[t];
} else {
ap_uint<32> s0 =
rotr(W[(t - 15) & 15], 7) ^
rotr(W[(t - 15) & 15], 18) ^
(W[(t - 15) & 15] >> 3);
ap_uint<32> s1 =
rotr(W[(t - 2) & 15], 17) ^
rotr(W[(t - 2) & 15], 19) ^
(W[(t - 2) & 15] >> 10);
wt = W[t & 15] + s0 + W[(t - 7) & 15] + s1;
W[t & 15] = wt;
}
ap_uint<32> S1 = rotr(e, 6) ^ rotr(e, 11) ^ rotr(e, 25);
ap_uint<32> ch = (e & f) ^ ((~e) & g);
ap_uint<32> temp1 = h + S1 + ch + K[t] + wt;
ap_uint<32> S0 = rotr(a, 2) ^ rotr(a, 13) ^ rotr(a, 22);
ap_uint<32> maj = (a & b) ^ (a & c) ^ (b & c);
ap_uint<32> temp2 = S0 + maj;
h = g;
g = f;
f = e;
e = d + temp1;
d = c;
c = b;
b = a;
a = temp1 + temp2;
}
out.h[0] = iv.h[0] + a;
out.h[1] = iv.h[1] + b;
out.h[2] = iv.h[2] + c;
out.h[3] = iv.h[3] + d;
out.h[4] = iv.h[4] + e;
out.h[5] = iv.h[5] + f;
out.h[6] = iv.h[6] + g;
out.h[7] = iv.h[7] + h;
}
static void bitcoin_sha256d_midstate(
const digest256_t &midstate,
ap_uint<32> w0,
ap_uint<32> w1,
ap_uint<32> w2,
ap_uint<32> nonce,
digest256_t &out
) {
#pragma HLS INLINE off
digest256_t iv0;
digest256_t first;
ap_uint<32> block1[16];
ap_uint<32> block2[16];
#pragma HLS ARRAY_PARTITION variable=block1 complete
#pragma HLS ARRAY_PARTITION variable=block2 complete
sha256_init_iv(iv0);
// Bitcoin header chunk 2:
// 16 bytes payload + SHA-256 padding
block1[0] = w0; // merkle root tail
block1[1] = w1; // time
block1[2] = w2; // bits
block1[3] = nonce; // nonce
block1[4] = 0x80000000;
block1[5] = 0;
block1[6] = 0;
block1[7] = 0;
block1[8] = 0;
block1[9] = 0;
block1[10] = 0;
block1[11] = 0;
block1[12] = 0;
block1[13] = 0;
block1[14] = 0;
block1[15] = 640; // 80 bytes * 8 bits
sha256_compress_iv(block1, midstate, first);
for (int i = 0; i < 8; i++) {
#pragma HLS UNROLL
block2[i] = first.h[i];
}
block2[8] = 0x80000000;
block2[9] = 0;
block2[10] = 0;
block2[11] = 0;
block2[12] = 0;
block2[13] = 0;
block2[14] = 0;
block2[15] = 256; // 32 bytes * 8 bits
sha256_compress_iv(block2, iv0, out);
}
合成結果
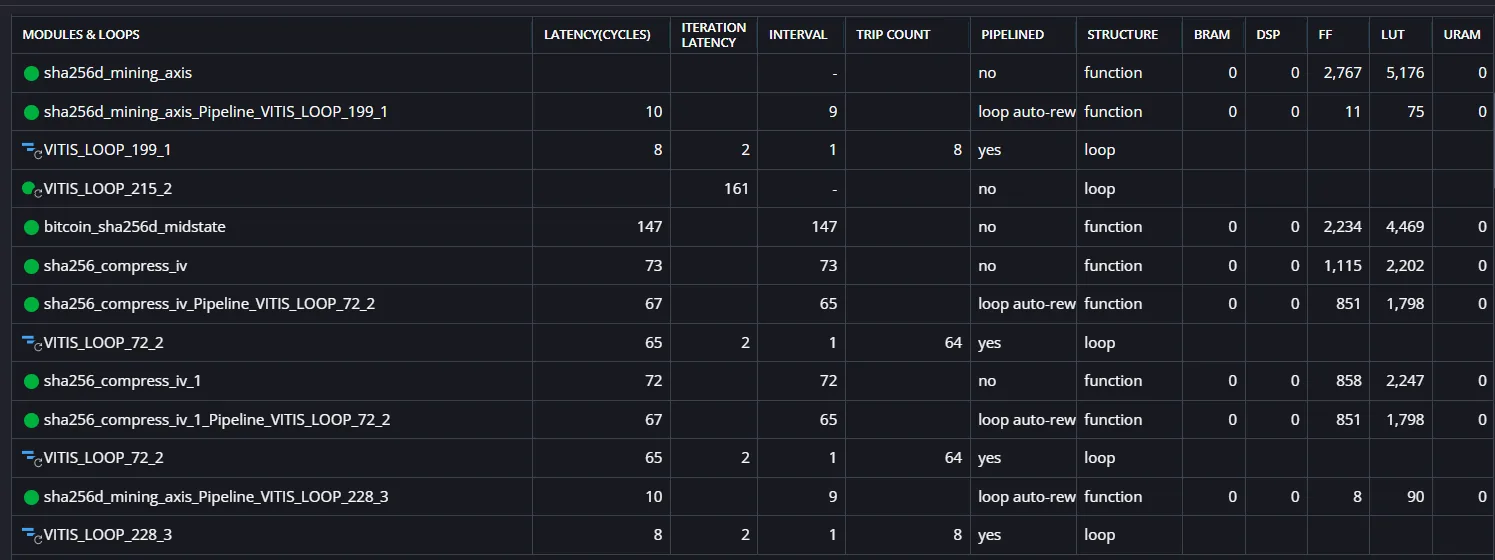
1回目SHA-256の第2チャンク圧縮が約73[cc]、2回目SHA-256圧縮が約72[cc]であり、合計で147ccとなった。
50MHz動作と仮定すると、ハッシュレートは約340kH/sとなる。
前回は約276kH/sなので、ビットコインマイニング向けの構造にするだけで性能が向上した。
SHA-256論理関数の関数化
以前にSHA-256のNISTの資料を読んで実装したときに、
$\operatorname{Ch}(x,y,z)$
$\operatorname{Maj}(x,y,z)$
$\Sigma_0(x)$
$\Sigma_1(x)$
$\sigma_0(x)$
$\sigma_1(x)$
を関数化して実装した記憶がでてきたので、高位合成でもやってみたい。
もとの実装では直接、
ap_uint<32> S1 = rotr(e, 6) ^ rotr(e, 11) ^ rotr(e, 25);
ap_uint<32> ch = (e & f) ^ ((~e) & g);
のように記述していた。
これを関数化した。
static inline ap_uint<32> Ch(ap_uint<32> x,
ap_uint<32> y,
ap_uint<32> z) {
#pragma HLS INLINE
return z ^ (x & (y ^ z));
}
static inline ap_uint<32> Maj(ap_uint<32> x,
ap_uint<32> y,
ap_uint<32> z) {
#pragma HLS INLINE
return (x & y) | (z & (x | y));
}
static inline ap_uint<32> Sigma0(ap_uint<32> x) {
#pragma HLS INLINE
return rotr(x, 2) ^ rotr(x, 13) ^ rotr(x, 22);
}
static inline ap_uint<32> Sigma1(ap_uint<32> x) {
#pragma HLS INLINE
return rotr(x, 6) ^ rotr(x, 11) ^ rotr(x, 25);
}
static inline ap_uint<32> sigma0(ap_uint<32> x) {
#pragma HLS INLINE
return rotr(x, 7) ^ rotr(x, 18) ^ (x >> 3);
}
static inline ap_uint<32> sigma1(ap_uint<32> x) {
#pragma HLS INLINE
return rotr(x, 17) ^ rotr(x, 19) ^ (x >> 10);
}
特に、$\operatorname{Ch}$と$\operatorname{Maj}$は、標準的な定義から等価変形した形を使った。
簡単な演算を省いただけなのでそこまで大きく変化するとは思っていないが…
$$ \begin{aligned} \operatorname{Ch}(x,y,z) &= (x \land y) \oplus (\neg x \land z) \ &= z \oplus \left(x \land (y \oplus z)\right). \end{aligned} $$
$$ \begin{aligned} \operatorname{Maj}(x,y,z) &= (x \land y) \oplus (x \land z) \oplus (y \land z) \ &= (x \land y) \lor \left(z \land (x \lor y)\right). \end{aligned} $$
また、ラウンド処理も関数化した。
static inline void sha256_round(
ap_uint<32> &a,
ap_uint<32> &b,
ap_uint<32> &c,
ap_uint<32> &d,
ap_uint<32> &e,
ap_uint<32> &f,
ap_uint<32> &g,
ap_uint<32> &h,
ap_uint<32> k,
ap_uint<32> w
) {
#pragma HLS INLINE
ap_uint<32> temp1 = h + Sigma1(e) + Ch(e, f, g) + k + w;
ap_uint<32> temp2 = Sigma0(a) + Maj(a, b, c);
h = g;
g = f;
f = e;
e = d + temp1;
d = c;
c = b;
b = a;
a = temp1 + temp2;
}
これによってラウンドのループは簡素化することができた。
for (int t = 0; t < 64; t++) {
#pragma HLS PIPELINE II=1
ap_uint<32> wt;
if (t < 16) {
wt = W[t];
} else {
wt = W[t & 15]
+ sigma0(W[(t - 15) & 15])
+ W[(t - 7) & 15]
+ sigma1(W[(t - 2) & 15]);
W[t & 15] = wt;
}
sha256_round(a, b, c, d, e, f, g, h, K[t], wt);
}
合成結果
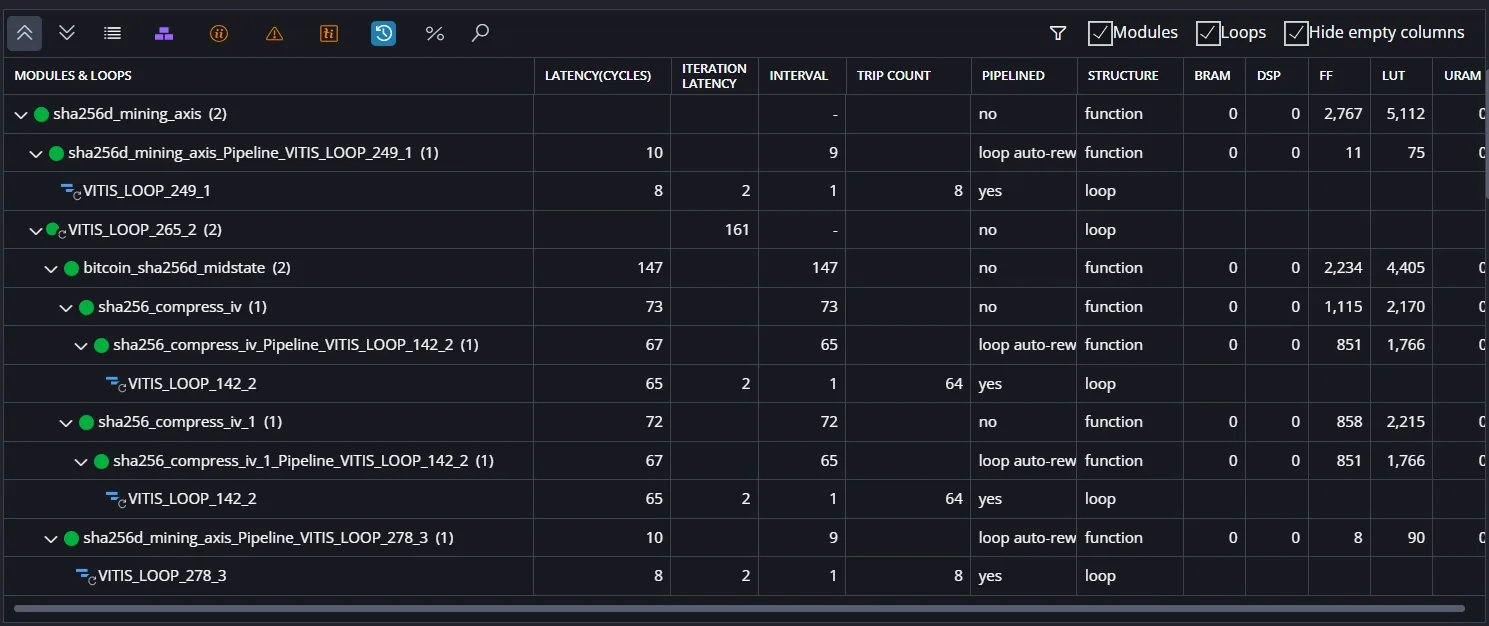
| 実施項目 | cycles/hash 目安 | LUT | FF |
|---|---|---|---|
| midstate入力対応 | 147 cycles | 5,176 | 2,767 |
| Ch/Maj等の関数化 | 147 cycles | 5,112 | 2,767 |
レイテンシは変わらなかったが、LUTは少し減少した。
この変更による効能としては、可読性の向上とLUTの若干の削減ができた。
Dataflow化
次に、SHA256dの2段構造をDataflow化した。
直列実装では、各nonceについて以下を順番に実行していた。
nonce i : SHA256-1 chunk2 → SHA256-2 → check
nonce i + 1 : SHA256-1 chunk2 → SHA256-2 → check
nonce i + 2 : SHA256-1 chunk2 → SHA256-2 → check
...
この場合、1 hashあたり約147ccかかる。
しかし、SHA256dは2段構造なので、1回目の処理と2回目の処理を別ステージに分けることができる。
| ステージ | 役割 | 入力データ | 出力データ |
|---|---|---|---|
| 1 | 第2チャンクの圧縮 | midstate、w0、w1、w2、nonce | first_digest |
| 2 | SHA256dの後段圧縮 | first_digest | final_digest |
Dataflow化後は、以下のように動作する。
| 時刻 | Stage 1 | Stage 2 |
|---|---|---|
| t | nonce i の 1 回目 SHA-256 | - |
| t+1 | nonce i+1 の 1 回目 SHA-256 | nonce i の 2 回目 SHA-256 |
| t+2 | nonce i+2 の 1 回目 SHA-256 | nonce i+1 の 2 回目 SHA-256 |
| t+3 | nonce i+3 の 1 回目 SHA-256 | nonce i+2 の 2 回目 SHA-256 |
つまり、stage1とstage2を重ねて動かすことで、スループットを改善できる。
実装
stage1とstage2の間をhls::stream<digest256_t>で接続した。
static void sha256d_mining_dataflow(
const digest256_t &midstate,
ap_uint<32> w0,
ap_uint<32> w1,
ap_uint<32> w2,
ap_uint<32> nonce_base,
hls::stream<axis32_t> &s_out,
int num_nonces
) {
#pragma HLS INLINE off
#pragma HLS Dataflow
hls::stream<digest256_t> first_stream;
#pragma HLS STREAM variable=first_stream depth=4
sha256_stage1_loop(
midstate,
w0,
w1,
w2,
nonce_base,
num_nonces,
first_stream
);
sha256_stage2_loop(
first_stream,
s_out,
num_nonces
);
}
stage1では、midstateから1回目SHA-256の結果を計算する。
static void sha256_first_from_midstate(
const digest256_t &midstate,
ap_uint<32> w0,
ap_uint<32> w1,
ap_uint<32> w2,
ap_uint<32> nonce,
digest256_t &first
)
stage2では、firstを読み出して2回目SHA-256を実行する。
static void sha256_stage2_loop(
hls::stream<digest256_t> &first_stream,
hls::stream<axis32_t> &s_out,
int num_nonces
) {
#pragma HLS INLINE off
for (int i = 0; i < num_nonces; i++) {
digest256_t first;
digest256_t out;
first = first_stream.read();
sha256_second_from_digest(first, out);
合成結果
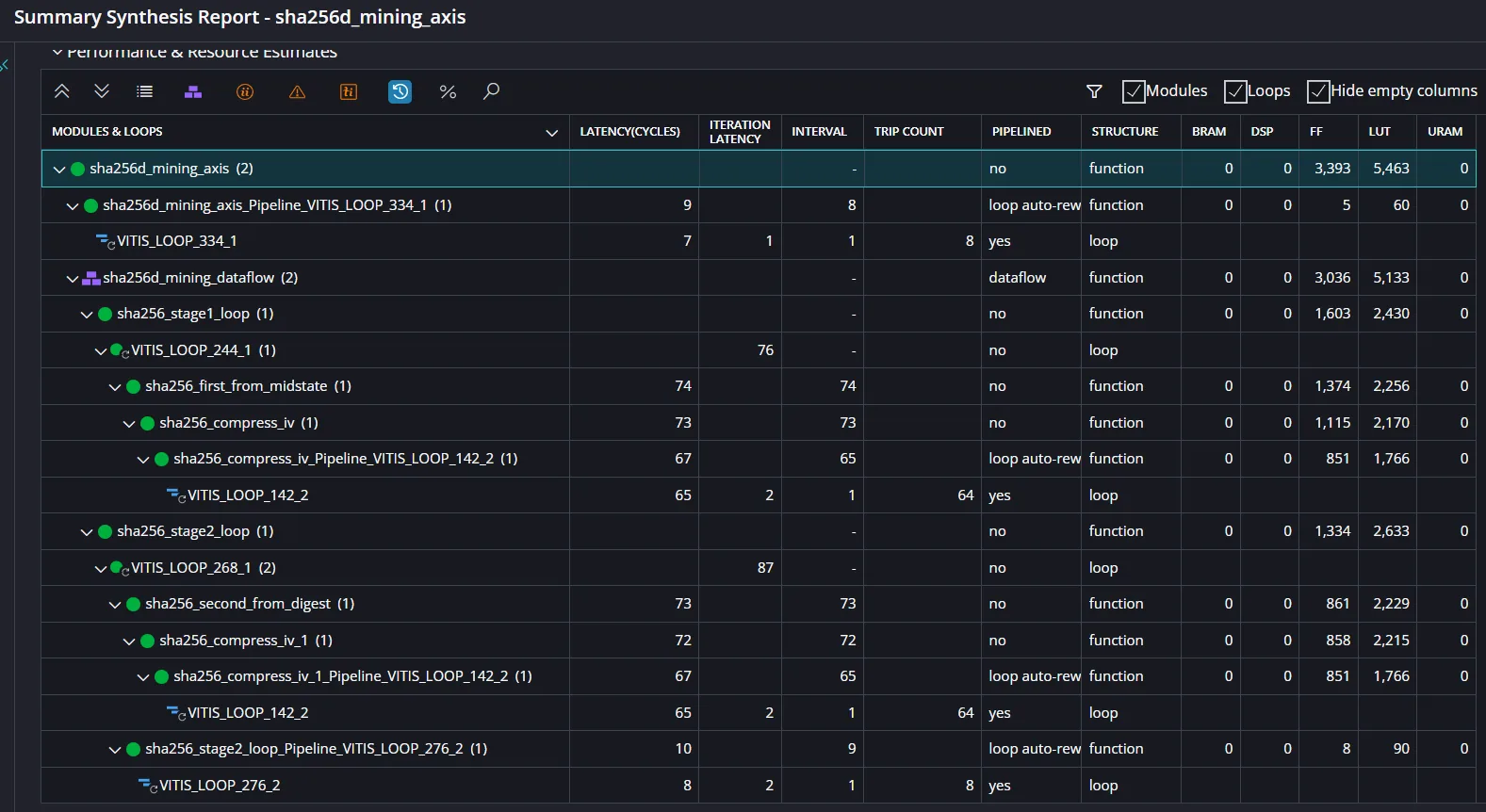
Dataflow化により、単純に147ccではなく、stage1とstage2の遅い方がスループットを支配するようになる。
この場合、stage2側が約87ccであるため、これにつられることとなる。
50MHz動作なら、理論的には約575kH/sとなる。
stage2が73ccではなく87ccになっているのは、2回目SHA-256圧縮に加えて、8ワードの出力処理も含んでいるためと考えられる。
PYNQ-Z2での実機検証
Dataflow化したものをbit generateして、実機検証した。
PS側では、疑似的な80バイトのヘッダを作り、最初の64バイトからmidstateを計算し、nonceの基準値などと一緒にPL側へ送信する。
PL側はnonce基準値から連続したnonceを走査して、それぞれのSHA256dを演算する。
pynqのテストコード
from pynq import Overlay, allocate
import numpy as np
import hashlib
import struct
import time
ol = Overlay("design_1.bit", download=True)
ip = ol.sha256d_mining_axis_0
dma = ol.axi_dma_0
dma.sendchannel._max_size = (1 << 23) - 1
dma.recvchannel._max_size = (1 << 23) - 1
K = [
0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,
0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5,
0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,
0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174,
0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,
0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da,
0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,
0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967,
0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,
0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85,
0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,
0xd192e819,0xd6990624,0xf40e3585,0x106aa070,
0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,
0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3,
0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,
0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2,
]
IV = [
0x6a09e667,
0xbb67ae85,
0x3c6ef372,
0xa54ff53a,
0x510e527f,
0x9b05688c,
0x1f83d9ab,
0x5be0cd19,
]
def rotr32(x, n):
return ((x >> n) | (x << (32 - n))) & 0xffffffff
def sha256_compress_ref(block_words, state):
assert len(block_words) == 16
assert len(state) == 8
W = [0] * 64
for i in range(16):
W[i] = int(block_words[i]) & 0xffffffff
for t in range(16, 64):
s0 = rotr32(W[t - 15], 7) ^ rotr32(W[t - 15], 18) ^ (W[t - 15] >> 3)
s1 = rotr32(W[t - 2], 17) ^ rotr32(W[t - 2], 19) ^ (W[t - 2] >> 10)
W[t] = (W[t - 16] + s0 + W[t - 7] + s1) & 0xffffffff
a, b, c, d, e, f, g, h = [int(x) & 0xffffffff for x in state]
for t in range(64):
S1 = rotr32(e, 6) ^ rotr32(e, 11) ^ rotr32(e, 25)
ch = (e & f) ^ ((~e) & g)
temp1 = (h + S1 + ch + K[t] + W[t]) & 0xffffffff
S0 = rotr32(a, 2) ^ rotr32(a, 13) ^ rotr32(a, 22)
maj = (a & b) ^ (a & c) ^ (b & c)
temp2 = (S0 + maj) & 0xffffffff
h = g
g = f
f = e
e = (d + temp1) & 0xffffffff
d = c
c = b
b = a
a = (temp1 + temp2) & 0xffffffff
state[0] = (state[0] + a) & 0xffffffff
state[1] = (state[1] + b) & 0xffffffff
state[2] = (state[2] + c) & 0xffffffff
state[3] = (state[3] + d) & 0xffffffff
state[4] = (state[4] + e) & 0xffffffff
state[5] = (state[5] + f) & 0xffffffff
state[6] = (state[6] + g) & 0xffffffff
state[7] = (state[7] + h) & 0xffffffff
return state
def make_dummy_header_words():
return np.array([
0x01000000, 0x11111111, 0x22222222, 0x33333333,
0x44444444, 0x55555555, 0x66666666, 0x77777777,
0x88888888, 0x99999999, 0xaaaaaaaa, 0xbbbbbbbb,
0xcccccccc, 0xdddddddd, 0xeeeeeeee, 0xffffffff,
0x12345678, 0x5f5e1000, 0x1d00ffff, 0x00000000,
], dtype=np.uint32)
def calc_midstate_from_header_words(header_words):
state = IV.copy()
block0 = [int(x) for x in header_words[:16]]
return sha256_compress_ref(block0, state)
def calc_expected_from_midstate(midstate, w0, w1, w2, nonce):
first = [int(x) for x in midstate]
block1 = [0] * 16
block1[0] = int(w0) & 0xffffffff
block1[1] = int(w1) & 0xffffffff
block1[2] = int(w2) & 0xffffffff
block1[3] = int(nonce) & 0xffffffff
block1[4] = 0x80000000
block1[15] = 640
first = sha256_compress_ref(block1, first)
second = IV.copy()
block2 = [0] * 16
for i in range(8):
block2[i] = first[i]
block2[8] = 0x80000000
block2[15] = 256
second = sha256_compress_ref(block2, second)
return np.array(second, dtype=np.uint32)
def words_to_hex_be(words):
return b"".join(int(x).to_bytes(4, "big") for x in words).hex()
def run_pl_mining(num_nonces=16, repeat=5):
header_words = make_dummy_header_words()
midstate = calc_midstate_from_header_words(header_words)
w0 = int(header_words[16])
w1 = int(header_words[17])
w2 = int(header_words[18])
nonce_base = int(header_words[19])
in_buf = allocate(shape=(12,), dtype=np.uint32)
out_buf = allocate(shape=(num_nonces, 8), dtype=np.uint32)
for i in range(8):
in_buf[i] = midstate[i]
in_buf[8] = w0
in_buf[9] = w1
in_buf[10] = w2
in_buf[11] = nonce_base
in_buf.flush()
# warm-up
ip.write(0x10, num_nonces)
dma.recvchannel.transfer(out_buf)
dma.sendchannel.transfer(in_buf)
ip.write(0x00, 0x01)
dma.sendchannel.wait()
dma.recvchannel.wait()
out_buf.invalidate()
times = []
for _ in range(repeat):
in_buf.flush()
ip.write(0x10, num_nonces)
t0 = time.perf_counter()
dma.recvchannel.transfer(out_buf)
dma.sendchannel.transfer(in_buf)
ip.write(0x00, 0x01)
dma.sendchannel.wait()
dma.recvchannel.wait()
t1 = time.perf_counter()
out_buf.invalidate()
times.append(t1 - t0)
# 検証
ok_all = True
for i in range(min(num_nonces, 4)):
nonce = (nonce_base + i) & 0xffffffff
expected = calc_expected_from_midstate(midstate, w0, w1, w2, nonce)
got = out_buf[i].copy()
ok = np.array_equal(got, expected)
ok_all &= ok
print(f"nonce {i}: 0x{nonce:08x}")
print("PL :", words_to_hex_be(got))
print("expected :", words_to_hex_be(expected))
print("match :", ok)
print()
avg_hps = num_nonces / (sum(times) / len(times))
best_hps = num_nonces / min(times)
result = {
"match": ok_all,
"times": times,
"avg_hps": avg_hps,
"best_hps": best_hps,
"digest0": words_to_hex_be(out_buf[0]),
}
in_buf.close()
out_buf.close()
return result
res = run_pl_mining(num_nonces=4096, repeat=5)
print("match :", res["match"])
print("digest0 :", res["digest0"])
print("times :", res["times"])
print("PL avg :", res["avg_hps"], "hashes/s")
print("PL best :", res["best_hps"], "hashes/s")
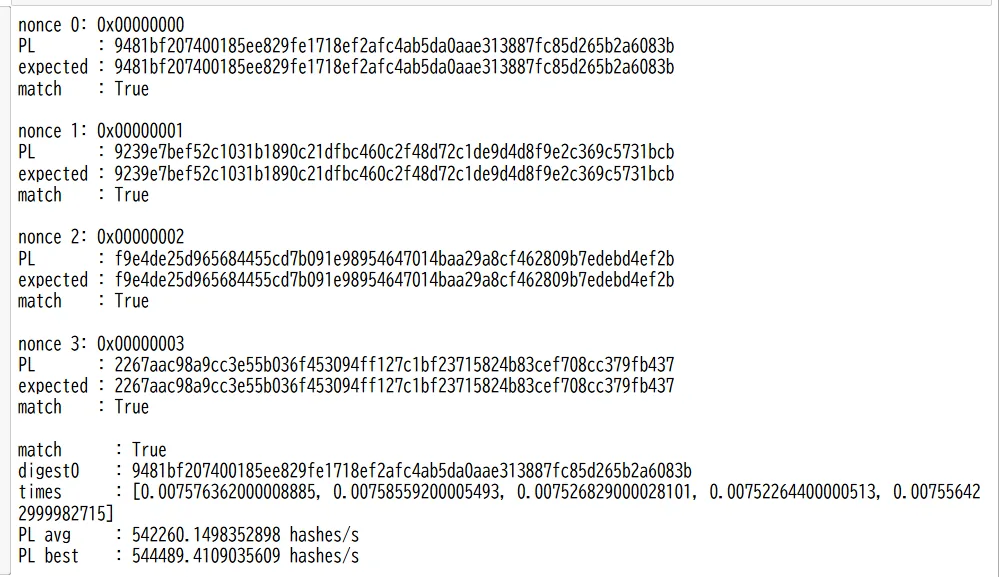
すべて一致したため、PL側の計算は正しく動作していると思われる。
性能計測
nonceの個数を変えながら、PYNQ上で性能を測定した。
for n in [1024, 4096, 16384, 65536, 131072, 262143]:
res = run_pl_mining(num_nonces=n, repeat=3)
print(n, res["avg_hps"], res["best_hps"])
| 性能\nonce数 | 1,024 | 4,096 | 16,384 | 65,536 | 131,072 | 262,143 |
|---|---|---|---|---|---|---|
| 平均 kH/s | 410.066 | 537.715 | 579.069 | 590.968 | 593.213 | 594.177 |
| 最高 kH/s | 423.450 | 538.982 | 580.403 | 591.196 | 593.279 | 594.235 |
nonceの個数が少ない場合、DMA転送や制御処理のオーバーヘッドが相対的に大きくなるため、スループットは低めになる。
一方で、65536個以上になると、オーバーヘッドが無視できるようになり、約594kH/sで動作し、それ以上は増加しにくい。
50MHzと仮定し594kH/sの場合、約84ccでの動作となる。
これは合成時のレポートの約87ccと近い。
| 実施項目 | cycles/hash 目安 | LUT | FF |
|---|---|---|---|
| midstate入力対応 | 147 cycles | 5,176 | 2,767 |
| Ch/Maj等の関数化 | 147 cycles | 5,112 | 2,767 |
| Dataflow化 | 約 84〜87 cycles | 5,463 | 3,393 |
考察
今回の最適化ではDataflow化が最も効果的であった。
SHA256dは
first = SHA256(header)
out = SHA256(first)
という構造になっており、直列に処理すると、1回目の処理と2回目の処理のレイテンシがそのまま加算される。
一方、Dataflow化すると、1つ前のnonceの2回目SHA-256を処理している間に、次のnonceの1回目SHA-256を処理できる。そのため、スループットは2つのステージのうち遅い方で決まる。
また、性能計測にてnonceの数を多くすることで、理論値に近いの性能を発揮することができた。
今後、ハッシュ値を出力せずにPL内部でマイニングに必要な基準値との比較を行い、それに該当したnonceだけを返すようにすれば、stage2の負荷を少し下げられる可能性がある。
次回以降、それら最適化を実施したい。
また、ある程度シリアルでの高速化が実施できたら、FPGAのリソースをフルに使った並列化にも取り組みたい。